
Podejście bezklasowe
Kształtowanie i ograniczanie przepustowości
Do kontroli przepustowości w sieci wykorzystywane są dwa algorytmy, cieknącego wiadra (ang. Leaky bucket), oraz wiadra z żetonami (ang. Token bucket). Algorytmy te pozwalają ograniczyć prędkość, z jaką pakiety są wpuszczane do domeny QoS, zatem nie pozwalają na wprowadzenie do sieci nadmiernej ilości pakietów. Idea [24] algorytmu cieknącego wiadra powstała już w 1986 roku.
Cieknące wiadro
Podstawą działania algorytmu jest pojedynczy bufor – kolejka FIFO w której gromadzone są pakiety. Pakiety wybierane są z kolejki przy zachowaniu zasady, że sumaryczna wielkość pakietów, która została wysłana w jednostce czasu jest stała i ściśle zdefiniowana jako parametr całej procedury. Taki algorytm gwarantuje, że pakiety wejściowe, pojawiające się w różnych odstępach czasu i z różnym natężeniem, na wyjściu zachowują stały interwał. Rysunek 5.1 pokazuje działanie algorytmu.
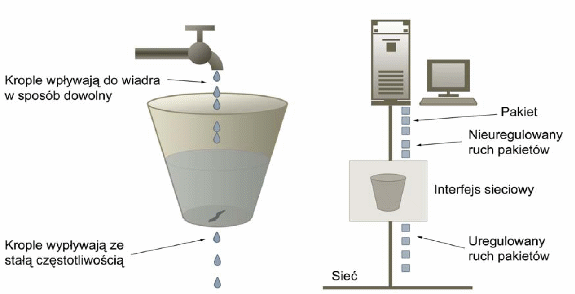
Pakiety przychodzące mogą zostać odrzucone na skutek przedawnienia lub przepełnienia. Algorytm nie pozwala na chwilowe wzrosty natężenia ruchu zaraz po jego rozpoczęciu. Jest to szczególnie pożądane, gdy istnieje potrzeba szybkiego przesłania większej liczby informacji przez krótką chwilę, np. oznaczonego przepływu Niedogodność tą niweluje omówiony dalej algorytm wiadra z żetonami.
Wiadro z żetonami
Działanie algorytmu wykorzystuje również wykorzystuje bufor, jednak w tym przypadku przechowujący żetony. Każdy żeton umożliwia przesłanie określonej ilości informacji, po wykorzystaniu żeton zostaje zniszczony.
Ograniczenie wykorzystania przepustowości i ustabilizowanie przepływu uzyskiwane jest dzięki stałemu w czasie generowaniu nowych żetonów. Jednak ich liczba nie może przekroczyć maksymalnej pojemności bufora. W sytuacji gdy nie ma danych wejściowych, żetony są gromadzone do maksymalnej wartości i mogą zostać użyte do wysłania zwiększonej liczby pakietów, lub obsłużenia nagłych wzrostów natężenia ruchu.
Przekroczenie rozmiaru bufora powoduje odrzucanie pakietów, a nie żetonów.
Na rysunku 5.2 widać, że fakt zgromadzenia w buforze pewnej dodatkowej liczby żetonów pozwala na wysłanie pakietów pojawiających się na początku z taką prędkością w jakiej wchodzą one do kolejki.
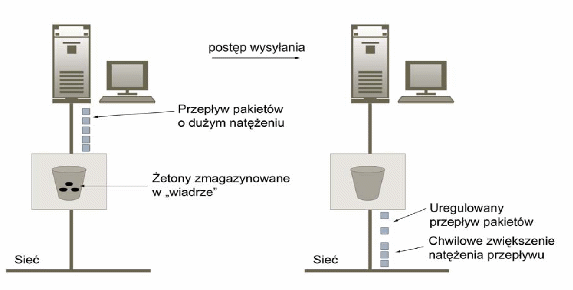
Algorytm ten, podobnie jak „cieknące wiadro”, umożliwia określenie z jakim natężeniem dane będą wysyłane. Jednak w odróżnieniu od poprzednio omawianego, pozwala, aby ruch wychodzący zmieniał się częściowo w zależności od stopnia nasilenia żądań wysyłania pakietów.
Mechanizm wiadra z żetonami, stosowany na wejściu do domeny DiffServ, spełnia następujące założenia:
n–bajtowe pakiety przychodzące są oznaczane jako zgodne, jeśli jest co najmniej n żetonów (zasada 1 bajt – 1 żeton) ,
jeśli w danej chwili liczba żetonów k jest mniejsza niż długość pakietu n, pakiet oznaczany jest jako niezgodny,
pakiety przychodzące przyjmowane są do sieci tak długo, dopóki nie wyczerpie się liczba żetonów,
jeśli nie ma pakietów do wysłania, żetony są gromadzone do maksymalnej wielkości k, reszta jest odrzucana.
O krokach podjętych dla pakietów zgodnych i niezgodnych decyduje kontrakt SLA.
Jeśli pakiety nie są zgodne, można podjąć następujące akcje [36]:
pakiet może zostać odrzucony,
pakiet może zostać ponownie oznaczony w szczególny sposób,
pakiet może zostać zbuforowany przez umieszczenie kolejki między strumieniem danych przychodzących, a wejściem do właściwej kolejki algorytmu. Pozwala to na uzupełnienie żetonów w wiadrze i umożliwienie wpuszczenia całego pakietu.
Zapewnienie sprawiedliwego dostępu do zasobów
Do zapewnienia sprawiedliwego dostępu do zasobów wykorzystuje się najczęściej kolejkowanie priorytetowe. Tworzonych jest wiele kolejek dla każdego z interfejsów, każdej z kolejek przypisany jest odpowiedni priorytet. W zależności od kontraktu SLA, ustalana jest zasada, do której kolejki zostanie przypisany konkretny rodzaj ruchu. Następnie algorytm przepuszcza w pierwszej kolejności kolejki o najwyższym priorytecie, a dopiero później kolejki o niższych priorytetach. Kolejkowanie priorytetowe jest dużo lepszym rozwiązaniem od kolejek FIFO, jednak dla aktualnie wykorzystywanego bufora przeznaczona jest cała dostępna przepustowość łącza, co jest wadą z punktu widzenia domeny QoS. Istnieje również możliwość zatrzymania ruchu o niskim priorytecie, dlatego algorytmy kolejkowania łączone są z algorytmami sprawiedliwego wyboru, np. stochastycznym, ważonym.
Algorytm Round Robin [5]
Ideą algorytmu Round Robin, przedstawionego na rysunku 5.3, jest stworzenie tylu kolejek ile jest przepływów, oraz zdejmowanie pakietów po jednym z każdego pasma w stałym porządku. W przypadku braku pakietów w danej kolejce, algorytm przechodzi do kolejnej nie tracąc czasu.
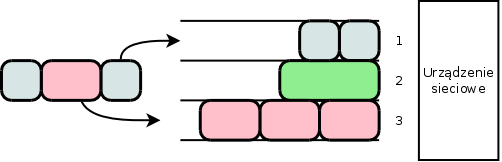
Istotną wadą algorytmu jest sytuacja, w której dwa źródła nadają pakiety z jednakową szybkością, ale pakiety drugiego źródła są znacznie większe (rys. 5.3, kolejki 1 i 2 ). W takim przypadku, w każdym cyklu, drugie źródło nada ponad dwukrotną ilość informacji.
Istnieją dwie odmiany mechanizmu, ważona i deficytowa.
Weighted Round Robin WRR
Do każdego połączenia przypisana jest waga. Wagi te są normalizowane tak, by najmniejsza waga była jak najbliżej jedynki, a równocześnie inne wagi pozostały całkowite, po czym służą za wyznacznik ile pakietów z danej kolejki może być zdjętych na raz podczas jednego okresu.
Deficit Round-Robin DRR [21]
Każdemu przepływowi przypisana jest pewna kumulująca się pula bajtów, które może wysłać podczas jednego cyklu. Podczas wyboru następnej kolejki, przepływ otrzymuje dodatkową pulę zwaną kwantem. Dla poszczególnych kolejek kwanty mogą mieć różną wielkość zależną od charakteru danego przepływu. Po wysłaniu pakietu przeznaczona na ten cel część puli bajtów zostaje odebrana kolejce. Pozostała zaś część nazywana jest deficytem i pozostaje w kolejce do następnej wysyłki. W przypadku, gdy pakiet nie przekracza długości deficytu, kwant nie jest dodawany.
Na rysunku 5.4 zostały przedstawione dwa kolejne kroki algorytmu. Dla każdego połączenia kwant wynosi 500. Pakiet o wielkości 400 mógł zostać wysłany, deficyt wynosi 100. Pakiet o długości 600 nie zostanie wysłany, ponieważ jest dłuższy niż aktualny kwant, dopiero w kolejnym cyklu zostanie obsłużony, kiedy do deficytu zostanie dodany kolejny kwant.
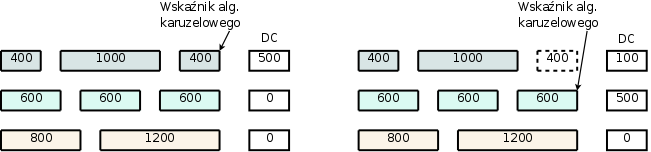
Algorytmy karuzelowe są standardowym modelem dostępu do zasobów w sieciach gwarantujących QoS. Są zaimplementowane w większość kolejek sprawiedliwego dostępu jako sposób odbierania pakietów z kolejki.
Kolejka SFQ (ang. Stochastic Fairness Queuing) [13]
W kolejce tworzona jest kolejka FIFO dla każdego z poszczególnych przepływów, nazwanych konwersacjami. Pojedyncza konwersacja składa się z grupy pakietów posiadających takie same adresy źródłowe i docelowe, oraz typy używanych protokołów. Grupowanie odbywa się za pomocą funkcji haszującej, która na podstawie parametrów pakietu generuje numer kolejki. Nadany identyfikator jest unikalny, ale liczba kolejek jest skończona, więc może się zdarzyć, że kilka konwersacji będzie się znajdowało w jednej kolejce. Jeśli dwie kolidujące ze sobą konwersacje trafią do jednej kolejki, algorytm praktycznie przestaje działać. Dlatego SFQ co jakiś czas (na przykład kilka sekund) zmienia funkcje haszującą, kolizje mogą się więc pojawiać tylko przelotnie.
Poszczególne kolejki obsługiwane są w porządku karuzelowym, według algorytmu Round Robin. Zasadę działania algorytmu ilustruje rysunek 5.5.
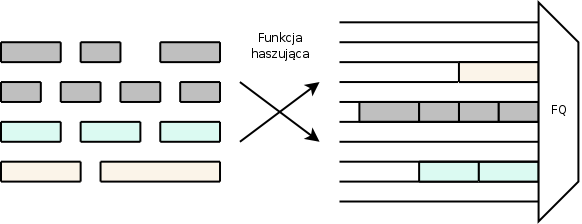
Wykorzystanie mechanizmu SFQ jest znikome, można zaimplementować go w końcówkach sieci opartych o system Linuks, ale lepszym wyborem są kolejki WFQ lub klasowy CBWFQ. Poza tym, w już istniejących sieciach QoS, algorytm SFQ jest zastępowany wyżej wymienionymi kolejkami ze względu na to że występuje duża trudność pogodzenia kolejki SFQ z innymi algorytmami kształtowania ruchu.
Kolejka WFQ (ang. Weighted Fairness Queuing)
Ważone sprawiedliwe kolejkowanie, podobnie jak SFQ zakłada wykorzystanie wielu odrębnych buforów dla różnych typów ruchu. Każda kolejka otrzymuje priorytet nadany dzięki zastosowaniu ustalonych kryteriów. Dodatkowo , poza priorytetem nadawana jest waga proporcjonalna do ustalonego priorytetu. Waga gwarantuje to, że bufory o wyższych priorytetach będą mogły wykorzystać większą przepustowość.
Opróżnianie kolejek odbywa się przy zastosowaniu algorytmu BR (ang. Bit-by-bit Round-Robin), który cyklicznie wybiera z każdej kolejki po jednym bicie. Pakiet zostaje wysłany gdy ostatni jego bit opuści bufor. Zapewnia to sprawiedliwość kolejki dla pakietów o różnych długościach.
Dokładna ilość przepustowości jaką każda kolejka otrzymuje, jest jednak zależna od liczby kolejek, które w tym samym czasie korzystają z łącza i nie może być dokładnie określona.
Przykładowo mając trzy kolejki o wysokim priorytecie i dwie o niskim, w sytuacji gdy pakiety oczekują na wysłanie w jednej kolejce o wysokim priorytecie i w dwóch o niskim, wówczas kolejka o wysokim priorytecie otrzyma połowę dostępnej przepustowości, a pozostałe dwa bufory po jednej czwartej. Jeśli zaś pakiety pojawią się tylko w trzech kolejkach o wysokim priorytecie, to każda z tych kolejek będzie mogła wykorzystać po jednej trzeciej dostępnej przepustowości.
Kolejka WFQ zapewnia każdej klasie ruchu dostęp do łącza, ale nie gwarantuje określonej przepustowości. Jest podstawową kolejką wykorzystywaną w domenach DiffServ i architekturze IntServ. Protokół sygnalizacyjny RSVP używa kolejki WFQ do przydzielenia miejsca w buforze pakietów, ustawiania harmonogramu obsługi, oraz do gwarantowania szerokości pasma i rezerwacji przepływu. Dzięki kolejce WFQ możliwe jest połączenie usług zintegrowanych z zróżnicowanymi. Jest najczęściej stosowaną kolejką w urządzeniach sieciowych. Przeprowadzona symulacja potwierdza, że kolejka WFQ jest najbardziej optymalnym wyborem spośród kolejkowania bezklasowego.
Kontrola przeciążeń
Standardowym zachowaniem kolejek wejściowych w urządzeniach domeny QoS podczas nadmiaru pakietów jest odrzucanie nadmiaru (ang. "tail-drop"). Taki mechanizm powoduje retransmisje niedostarczonych pakietów, a to z kolei doprowadza do ponownego zalania kolejki. Kolejne retransmisje mają charakter lawinowy i potrafią skutecznie zapchać ruch wejściowy, efektem też są duże opóźnienia lub też straty pakietów, co zupełnie kłóci się z ideą QoS. Powyższe zagrożenie można załagodzić implementacją długiej kolejki, ale zwiększa to opóźnienia i powoduje pakietyzację ruchu – wysyłanie serii pakietów w małych grupach. Ponadto, po wyczerpaniu się miejsca w kolejce, będą występowały kolejne utraty pakietów i kolejne retransmisje. W 1993 roku została opracowana koncepcja mechanizmu zapobiegania przeciążeniom RED [17], która w kolejnych latach była udoskonalana i z powodzeniem implementowana w urządzeniach sieciowych.
Mechanizm RED (ang. Random Early Detection)[33]
Jest to algorytm mający na celu unikanie przeciążeń przez wykorzystanie mechanizmów istniejących juz w protokole TCP. RED przewiduje wystąpienie przeciążenia łącza i gubi pakiety, sygnalizując tym samym nadawcy, że powinien ograniczyć transmisje. Po zakończeniu przeciążenia, automatycznie powraca do optymalnej prędkości wysyłania pakietów. Charakterystyczną cechą algorytmu jest to, że zapobiega on przeciążeniu zanim ono wystąpi, a nie tylko minimalizuje jego skutki w czasie jego trwania. Pierwszym krokiem po przyjęciu nowego pakietu przez RED jest obliczenie średniego rozmiaru kolejki (w bajtach) będącego funkcja poprzedniej średniej oraz obecnego rozmiaru. Na tej podstawie ,oraz dwóch administracyjnie ustalonych parametrów min i max, RED oblicza prawdopodobieństwo z jakim pakiet powinien zostać odrzucony. Prawdopodobieństwo to rośnie wraz ze wzrostem nasycenia łącza, aż do odrzucenia pakietu. Konsekwencją takiego działania jest większe prawdopodobieństwo odrzucania pakietów ze źródeł generujących większy ruch. Rysunek 5.6 ilustruje działanie algorytmu działającego w ruterze firmy CISCO[25]
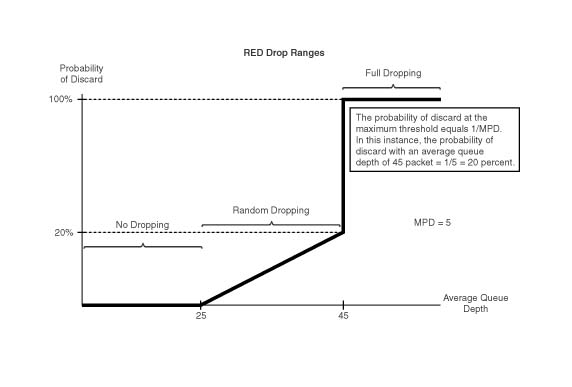
RED odrzuca losowo wybrane pakiety, istnieje więc możliwość odrzucenia pakietów ruchu o wysokim priorytecie. Modyfikacją RED, która eliminuje ten problem, jest mechanizm WRED (ang. Weighted Random Early Detection) zilustrowany na rysunku 5.7. W przeciwieństwie do zwykłego reagowania na przeciążenia, WRED potrafi rozpoznawać klasy ruchu zapisane w polu DSCP w nagłówku pakietu. Pozwala to na oddzielne definiowanie prawdopodobieństwa odrzucania ruchu w zależności od jego istotności. Przykładowo w mniejszym stopniu odrzucane będą pakiety generowane przez aplikacje czasu rzeczywistego, a w większym pozostałe.
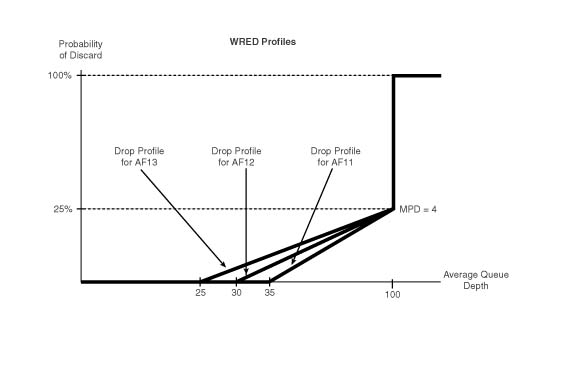
Powyżej pewnego stopnia natężenia ruchu mechanizm działa jak RED, tj. odrzuca cały ruch losowo.
Istnieją różne modyfikacje algorytmu, dostosowywanych do różnych sytuacji głównie ze względu na nierównomierność ruchu oraz sprawiedliwość podziału pasma, np. ARED (ang. Adaptive RED / Active RED) [4].
Algorytm RED i WRED są stosowane w domenie DiffServ jako podstawowa ochrona przed przeciążeniami.
Mechanizm Blue [10]
W sytuacji, gdy natężenie napływających pakietów jest duże, ciężko jest ustalić parametry RED w taki sposób, by efektywność odpowiadała potrzebom ruchu. W 1999 roku został przedstawiony algorytm Blue, funkcjonujący jak RED, ale potrafiący się sam konfigurować. W związku z tym należało zerwać z podstawowymi założeniami RED. Przede wszystkim, należało porzucić wykrywanie przeciążenia jedynie na podstawie zajętości bufora. Taka informacja jest niewystarczająca by określić wielkość przeciążenia.
W algorytmie Blue wykrywanie przeciążenia opiera się bezpośrednio na utracie pakietów i stopniu wykorzystania pasma. Algorytm przechowuje pojedynczą zmienną pm, która oznacza prawdopodobieństwo odrzucenia pakietu w momencie kolejkowania. Jeśli łącze odrzuca pakiet z powodu przepełnienia bufora, zmienna rośnie, natomiast jeśli łącze jest nieaktywne, zmienna pm maleje. Powoduje to swoisty sposób uczenia się właściwego prawdopodobieństwa z jakim należy odrzucać pakiety by nie doprowadzić do przeciążenia, adaptuje się do nowej sytuacji w momencie zmiany charakterystyki ruchu.
W roku 2001 został zaprezentowany algorytm SFB (ang. Stochastic Fair Blue) [11], który łączy w sobie cechy RED/Blue i kolejki SFQ.
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.